XMLデータベース(XML-DB)「NeoCore」
国内シェアNo.1のXMLデータベース「NeoCore」
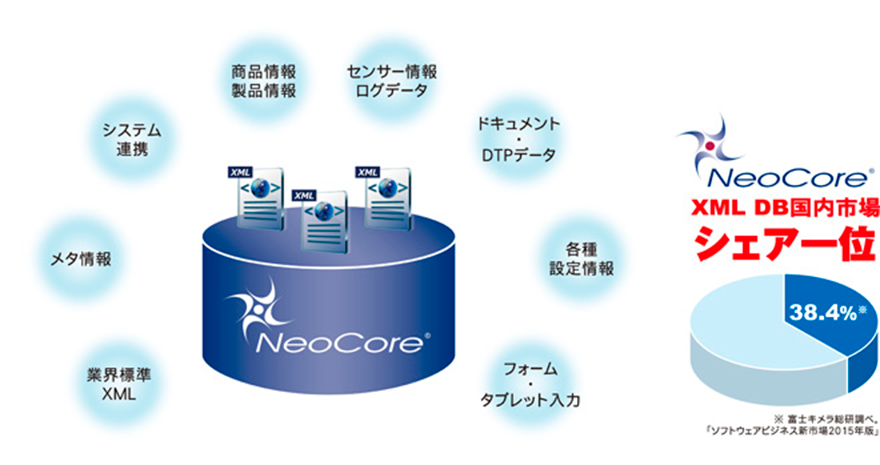
国内シェアNo.1のXMLデータベース(XML DB)「NeoCore」は、国内出荷実績が物語る、XMLデータベースのスタンダード製品です。構造化文書の標準フォーマットとして普及しているXMLを「なんでも・はやく・カンタンに」扱えるので、検索エンジンでは不可能な高機能検索(属性検索)にて、目的のコンテンツやドキュメントを素早く探し出すことが可能です。
特徴1.XMLデータのスキーマ定義不要
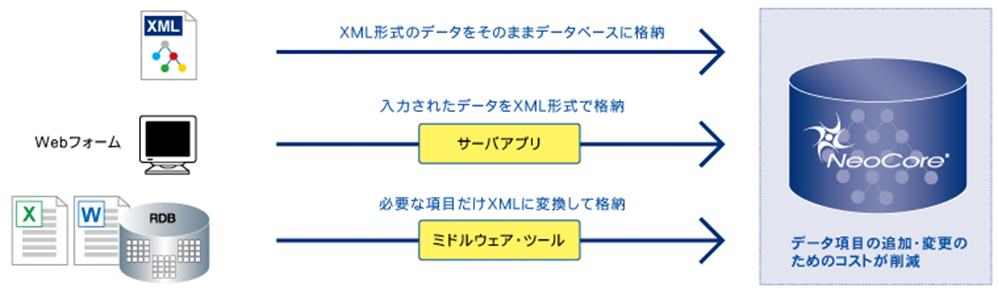
XML-DB「NeoCore」は、XML形式のデータを格納する際、スキーマを定義する必要がありません。格納、更新などの操作の際に入力するXMLについては、妥当性検証(Validationチェック)を行わず、整形式であるかどうかのチェック(Parsing)のみを行います。従って、DTDやXMLSchemaとは関係なく、あらゆるXML形式のデータを格納し、またエレメントの追加や削除を自由に行うことができます。
リレーショナルデータベース(RDB)は、格納するデータすべてのデータについて、厳密なスキーマ定義を必要とするため、仕様変更のたびにスキーマを再定義する必要がありました。これに対して、「NeoCore」を用いたデータベース設計では、ノードや属性をTree型に配置した構造を設計し、パフォーマンスを考慮したTree構造の変更を行います。リレーショナルデータベース(RDB)の場合はインプリメントの前に構造設計が完結している必要がありますが、「NeoCore」の場合は、基礎が決まっていれば、ある程度の変更はアプリケーションで吸収できてしまいます。
これにより、ビジネスサイドからの要求によって発生するスキーマ設計とインデックス再設計にかかるシステムエンジニアコストと時間を大幅に削減することが可能となり、システム開発の初期の段階でデータ構造を厳密に定義できない場合や、システム運用フェーズでのデータ項目の追加変更の際には、大きなメリットとなります。
特徴2.XML超高速検索機能
リレーショナルデータベース(RDB)のテーブル構造にXMLデータをマッピングしたり、XMLデータ型の領域に格納した場合に、著しく検索性能が低下したりする場合があります。NeoCoreは、独自の特許技術であるDPP(Digital Pattern Processing)により、XMLのデータ量やXMLの階層構造の深さに依存しない安定した検索が可能です。
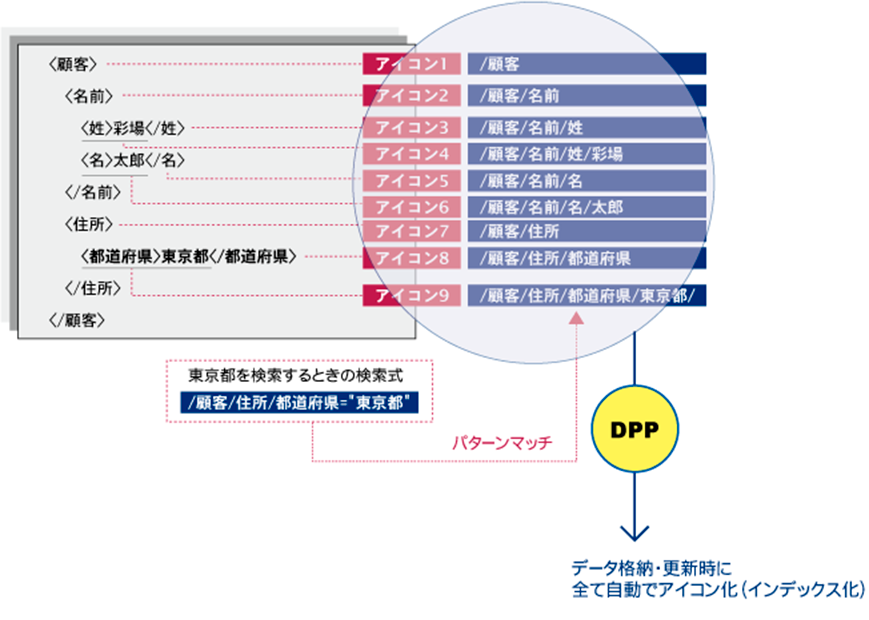
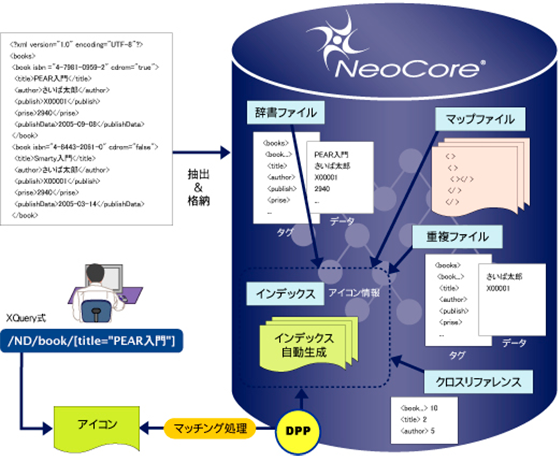
NeoCoreは、XMLデータを格納する際、Parsingを通過したXMLデータを、Flattenerと呼ばれるモジュールにより、パスとデータに分解します。DPPは、この分解した1つひとつのパスとデータを64bitの固定長のデータに変換し、すべてのタグに対してユニークな「アイコン」として生成します。
NeoCoreでは、データベースに格納されたXMLデータを検索する際に、元データを見ることなく、フラットな構造の「アイコン」をパターンマッチさせる方式を採用。この「アイコン」がXMLデータを検索する際のインデックスとして機能し、実データはこの「アイコン」が指し示す場所に格納されます。
特徴3.フルオートインデックス機能
XML-DB「NeoCore」は、XMLデータをデータベースに格納する際、DPP(Digital Pattern Processing)により、すべてのタグに対して自動的にインデックスを生成します。
フルオートインデックス機能は、リレーショナルデータベース(RDB)で必要とされるインデックス設計や生成のための作業を不要とします。つまり、開発者はどの項目にインデックスを設定すればよいかを考える必要はなく、インデックスを上手に使用するような検索方法を考えるだけで済むため、システム開発時の時間とコストを飛躍的に向上する事が可能です。NeoCoreは、格納時や更新時にDPPにより分解されたXMLの構造を、独自の方式でバイナリデータとして種類別に分類して格納します。
メーカーサイト https://www.cybertech.co.jp/xml/xmldb/neocore/